Built on Marin (an open LLM development community), this project started with a simple question: "If we tokenize large-scale audio data into discrete tokens, can we train a standard autoregressive transformer—in the same way we train text LLMs—to build a unified audio backbone where every audio-text task is just next-token prediction?"
We trained LLMs on sequences of discrete audio tokens, scaling from 135M to 4B parameters on 500B tokens. We leverage existing paired speech-text data by interleaving speech utterances with their transcripts at the utterance level. All training data is open (YODAS + Emilia).
Along the way, we investigated design choices (data sources, text pre-training data mixtures like Nemotron-CC), studied the scaling behavior of discrete audio models, and derived compute-optimal allocation strategies.
SODA is a unified pre-trained audio backbone where any audio-language task can be formulated as next-token prediction—through prompting and/or fine-tuning. Check out the Experiment Log for the full story of how we got here.
An interesting question for building foundation models is: how should we invest compute budget? This requires two pieces: (1) understanding how downstream capabilities change as validation loss (e.g., NLL on held-out speech data) decreases — do they improve rapidly, slowly, or plateau? and (2) if capabilities do improve with lower NLL — making it a meaningful optimization target — how should we allocate compute between model size and data to minimize it?
Scaling laws have been well-studied for text LLMs, but how do they apply to discrete audio models? So we trained 64 models across seven compute budgets (3×1018 to 3×1020 FLOPs), varying model size and data to find the sweet spot at each budget.
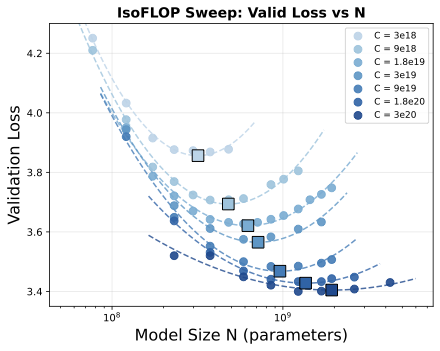
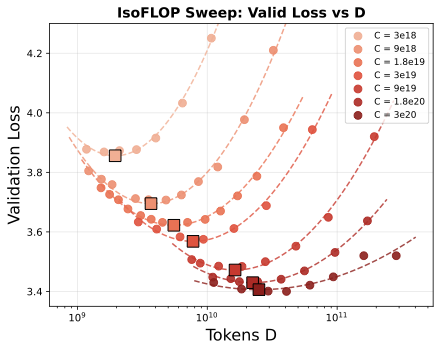
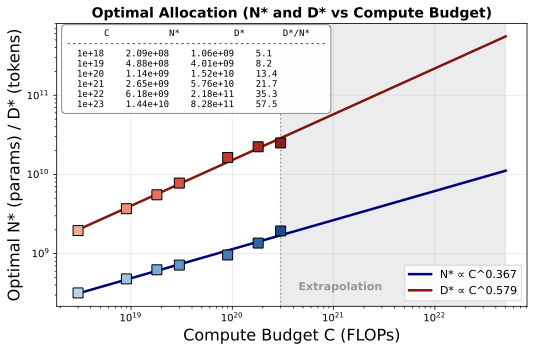
To the best of our knowledge, this is the first compute-optimal study for discrete audio models. Under our setup (100 audio tokens/sec with the Mimi tokenizer), optimal data grows 1.6× faster than optimal model size (N* ∝ C0.367, D* ∝ C0.579), landing in a similar ballpark to text LLM scaling studies that attributed this trend to the lower information density of training tokens.
Using those 64 models, we mapped how each capability (e.g., speech knowledge, ASR) improves as validation loss decreases. Then we trained our full SODA models (135M → 4B) and checked: do the trends hold? The SODA models (★) land right on the curves predicted by the smaller runs (●)—these results suggest that capabilities scale predictably similar to text LLMs.
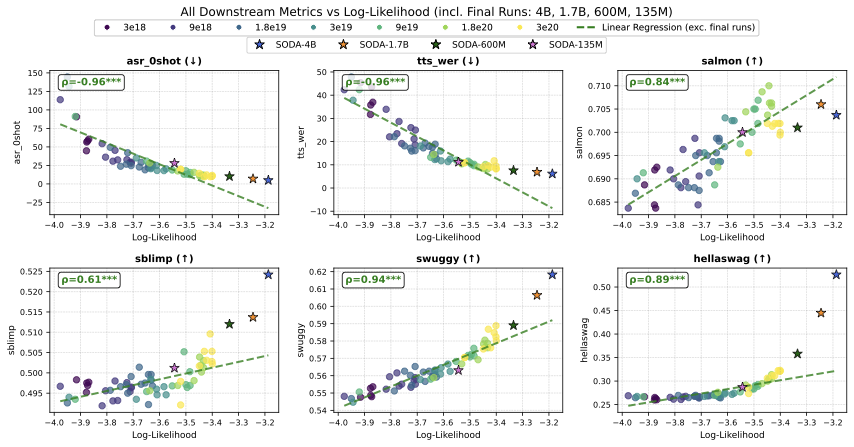
Note: The above shows that task performance is predictable given validation loss. We also explore predicting this final validation loss from model size and training tokens via a parametric fit — see Parametric Loss Prediction in the Experiment Log.
SODA treats all audio language tasks—whether text-to-audio, audio-to-text, or audio continuation—as simple next-token prediction problems. By doing utterance-level interleaving of discrete audio tokens with corresponding text tokens, we can formulate diverse tasks using standard prompting strategies. You can try SODA yourself in our 🎮 Interactive Demo.
Below is the pseudo-code for prompting SODA to perform audio continuation, zero-shot TTS, and ASR, as used in our demo:
# Audio Continuation
Prompt: <|audio_start|> {audio_context}
Predict: {continued_audio_tokens} # Text tokens (if generated) are omitted in audio conversion
# TTS (Unconditioned)
Prompt: <|text_start|> {text} <|text_end|> <|audio_start|>
Predict: {audio_tokens} <|audio_end|>
# TTS (Voice Conditioned)
Prompt: <|text_start|> {text} <|text_end|> <|audio_start|> {prompt_audio} <|audio_end|> \
<|text_start|> {target_text} <|text_end|> <|audio_start|>
Predict: {target_audio_tokens} <|audio_end|>
# Automatic Speech Recognition (ASR)
Prompt: <|audio_start|> {input_audio} <|audio_end|> <|text_start|>
Predict: {transcribed_text_tokens} <|text_end|>Note: Other audio-language tasks can be similarly formulated as next-token prediction, though effective performance on other tasks typically requires fine-tuning, as in-context learning has not yet emerged at this scale. See inference examples in SODA-4B-base.
*Speech prompts and corresponding baseline outputs are taken from existing project page demos (e.g., SIMS, SpiritLM, Llama-Mimi).
1) SpiritLM and SIMS model only semantic tokens with fixed vocoders, so they do not maintain voice characteristics in their continuations.
2) Llama-Mimi and SODA model both semantic and acoustic tokens, allowing them to maintain voice characteristics.
Source: SIMS Demo
Transcript: This is a story of a tiny talking computer
Model: SIMS-Qwen2.5-7B
Transcript: these computers are now in the pockets on the desks in the cars of many of you think of your names know where you
Transcript: because it eventually wasn't quite enough and through a number of life-changing times it's about a computer that changes the notion of who we are but how does it do any
Source: SIMS Demo
Transcript: The capital of England is
Model: SIMS-Qwen2.5-7B
Transcript: and ever has been the center of the wheel of Finance and here, the price of everything and everywhere
Transcript: Do you know what the City of London is? The city is the third largest city in the vertical index. It functions like analogy, but it doesn't use that word. The city of London was first created
Source: SpiritLM Demo (to demonstrate their expressive style transfer)
Transcript: Ha ha no I think you're thinking about Days of Thunder, which is a Tom Cruise racing movie
Model: SpiritLM-7B-Expressive
Transcript: oh God yeah this it was amazing was it was it the one where he was a monster between rocks and stars was
Transcript: yeah I got this idea for a girl who wants to know what life is like but important day for her is
Source: Llama-Mimi Demo
Transcript: 1,2,3,4,5,6
Model: Llama-Mimi-8B
Transcript: 7, 8, 9, 10, 11, 12, 9, 8 [5-second silence]
Transcript: 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6
Source: Llama-Mimi Demo
Transcript: This reality begins to explain the dark power
Model: Llama-Mimi-8B
Transcript: of the evil craftiness of the two brute stocks which might be unduly impatient of the painful rustlings of their hair and the loud bellowings of their dogs the constant efforts of the buddhists in the regions of the southern seas for an indefinite time
Transcript: influence, and intensity of life. This is Celestial Energy intense changes in life, contracts with expansion uplift and turns to down. Of harness, loss of life is true a
Description: A person speaks with some background music
Transcript: The Internet combines elements of both mass and interpersonal communication
Transcript: When I'm majoring in the engineering management and structure design program, I get the opportunity to work on the Sovereign West project.
Description: Multi-speaker recording between male and female
Transcript: [S1] Welcome to this English test! I'm John. What is your name? [S2] Hi, John. I'm Sarah. [S1] Do you work or are you a student?
Transcript: I'm a student. Do you live or are you staying this year? I live in apartment number five. What does your name say after six?
Transcript: Joe Keaton disapproved of films, and Buster also had reservations about the medium.
This speech is generated by our AI model and it is not real
Transcript: Hello everyone my name is William Held
Let me tell you about Marin. It is an open lab for building foundation models, together. We’re training powerful models from scratch, and sharing and programmatically documenting every step: the code, the data, the experiments, the mistakes…all in real-time. We invite anyone who shares our vision of open science and open-source to join and contribute, whether you want to try out a new architecture, training algorithm, dataset, evaluation…there is a lot to do!
lord kingsdown funded the kingsdown church
Lord Kingsdown funded the Kingsdown church
just then leocadia came to herself and embracing the cross seemed changed into a sea of tears and the gentleman remained in utter bewilderment until his wife had repeated to him from beginning to end leocadia's whole story and he believed it through the blessed dispensation of heaven which had confirmed it by so many convincing testimonies
Just then Leo Kadya came to herself, and embracing the cross, seemed changed into a sea of tears, and the gentleman remaining in utter bewilderment, until his wife had repeated to him, from beginning to end, Leo Kadya's whole story, and he believed it, through the blessed dispensation of heaven, which had confirmed it by so many convincing testimonies.
*Unlike the other examples on this page (which use the pre-trained SODA-4B-base), the samples below come from SODA-600M fine-tuned on CVSS-T for voice-preserving X→En translation. The fine-tuning uses the same decoder-only transformer and next-token-prediction objective—no architectural modifications, no speaker embedding modules, no separate decoder. The input sequence is simply formatted as: source audio → source text → target text → target audio. See §6.3 of the paper for full evaluation results.
Listen for how the generated English translation preserves the speaker's voice characteristics from the source audio.
Language: Spanish
SIM: 0.58
Source: Sin embargo, la canción sí fue incluida en la versión estadounidense del álbum.
Generated: however the song was included in the american version of the album
Language: German
SIM: 0.56
Source: Diese Interaktion war erfolgreich.
Generated: this interaction was successful
Language: Italian
SIM: 0.39
Source: Il nastro era completamente rosso.
Generated: the master was completely red
Language: Chinese
SIM: 0.61
Source: 位于锦州市西南部。
Generated: it is located in the city of xinampu
SIM = speaker similarity between source and generated audio. See Table 3 in the paper for full quantitative results.
@article{soda2026,
author = {Manakul, Potsawee and Gan, Woody Haosheng and Bartelds, Martijn and Sun, Guangzhi and Held, William and Yang, Diyi},
title = {Scaling Open Discrete Audio Foundation Models with Interleaved Semantic, Acoustic, and Text Tokens},
journal = {arXiv preprint arXiv:2602.16687},
year = {2026}
}